Intuitive Explanation of Connectionist Temporal Classificatoin
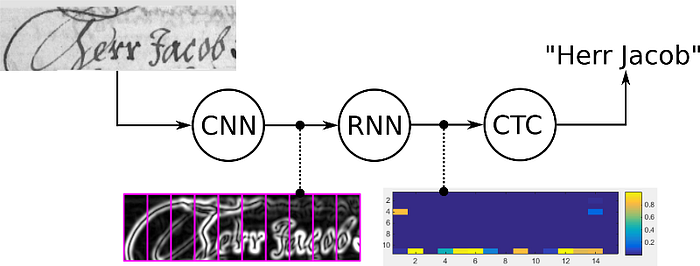
Why we want CTC
In previous approach, we need to create dataset with images of text lines, and specify the ground truth character for each horizontal position which is very time-consuming. We also need some further processing to get the final text from it.
CTC advantages:
- we only have to tell the CTC loss the text , ignore the position and width.
- no further processing of the recognized text is needed.
### How CTC works: It tries all possible alignment of the Ground Truth text in the image and takes the sum of all scores. This way, the score of a GT text is hign if the sum over the alignment-scores has a high value.
### Encoding introducing a pseudo-character (called blank, but don’t confuse it with a “real” blank, i.e. a white-space character). This special character will be denoted as “-” in the following text. when encoding a text, we can insert arbitrary many blanks at any position, which will be removed when decoding it. However, we must insert a blank between duplicate characters like in “hello”. Further, we can repeat each character as often as we like.
### Loss Function

The score for one alignment (or path, as it is often called in the literature) is calculated by multiplying the corresponding character scores together. In the example shown above, the score for the path “aa” is 0.4·0.4=0.16 while it is 0.4·0.6=0.24 for “a-” and 0.6·0.4=0.24 for “-a”. To get the score for a given GT text, we sum over the scores of all paths corresponding to this text. Let’s assume the GT text is “a” in the example: we have to calculate all possible paths of length 2 (because the matrix has 2 time-steps), which are: “aa”, “a-” and “-a”. We already calculated the scores for these paths, so we just have to sum over them and get 0.4·0.4+0.4·0.6+0.6·0.4=0.64. If the GT text is assumed to be “”, we see that there is only one corresponding path, namely “–”, which yields the overall score of 0.6·0.6=0.36.
We are now able to compute the probability of the GT text of a training sample, given the output matrix produced by the NN. The goal is to train the NN such that it outputs a high probability (ideally, a value of 1) for correct classifications. Therefore, we maximize the product of probabilities of correct classifications for the training dataset. For technical reasons, we re-formulate into an equivalent problem: minimize the loss of the training dataset, where the loss is the negative sum of log-probabilities. If you need the loss value for a single sample, simply compute the probability, take the logarithm, and put a minus in front of the result. To train the NN, the gradient of the loss with respect to the NN parameters (e.g., weights of convolutional kernels) is computed and used to update the parameters.
decode
A simple and very fast algorithm is best path decoding which consists of two steps: it calculates the best path by taking the most likely character per time-step. it undoes the encoding by first removing duplicate characters and then removing all blanks from the path. What remains represents the recognized text.