changes from EfficientNet Lite to EfficientNet.
- removed squeeze-excitation networks
- replaced all swish with RELU6
- Fixed the stem and head while scaling models up to reduce the size and computations of scaled models
chanllenges in edge devices.
- Quantization: many devices have limited floating-point support, quantization is widely used. challenge: complicated quantization-aware training procedure or poor post-traininig quantization model accuracy.
- Heterogeneous hardware: it is challenging to run the same model on a wide range of accelerators such as mobileGPU/edge TPU. due to the hardware specialization, these accelerators often perform well only for a limited set of operations. we found that some of the operations in EfficientNet are not well supported by certain accelerators.
– experience of post-training quantization: https://blog.tensorflow.org/2020/03/higher-accuracy-on-vision-models-with-efficientnet-lite.html
### EfficientDet:
Efficientnet backbone + BiFPN
#### BiFPN

#### Compound scaling for all parts, backbone, class/box prediction.
heuristic-based scaling approach rather than grid search for coefficients.
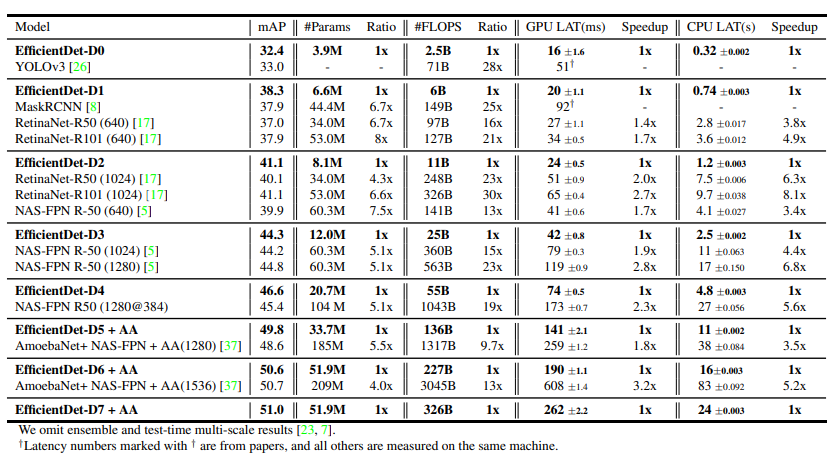
### result