Problems:
Most CNNs just stacked convolution layers deeper and deeper, hoping to get better performance.
The Inception network was complex(heavily engineered). It keeps evolving to get better speed and accuracy.
Each version of Inception Network is an iterative improvement over the previous one. Depending on users’ data, a lower version may actually work better.
Inception v1:
- Salient parts in the image can have extremely large variation in size.
- Because of this variation, choosing the right kernel size for the convolution operation becomes tough. A large kernel is preferred for information which is distributed more globally. Smaller kernel is preferrd for information that is distrbuted more locally.
- deep network are prone to overfitting.
- Naively stacking large convolution layers is computationally expensive.
Solution:
have filters with muliple sizes operate on the same level.
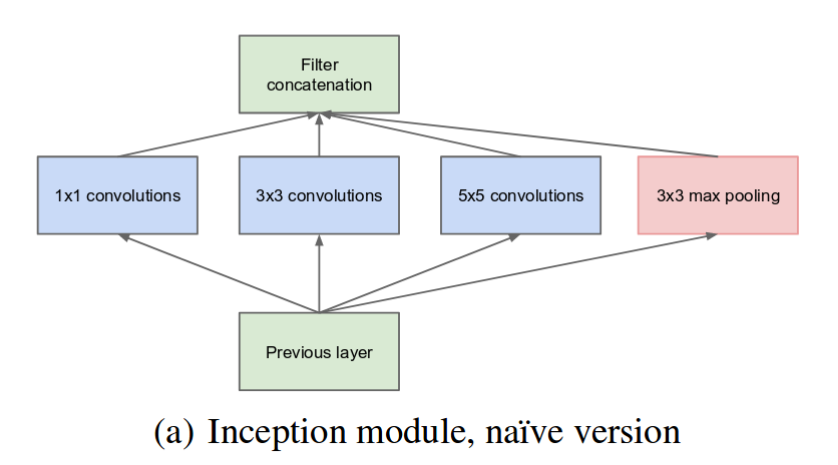 A naive module.
A naive module.
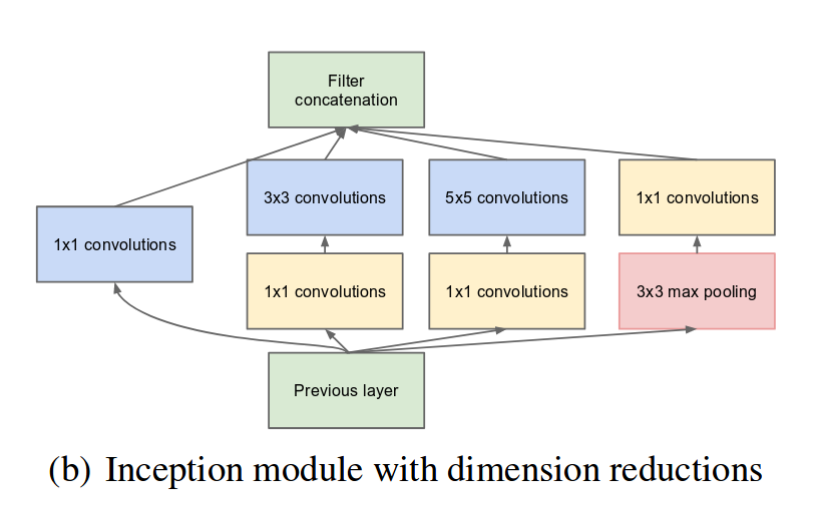
use 1x1 convolution to reduce the channels
https://machinelearningmastery.com/introduction-to-1x1-convolutions-to-reduce-the-complexity-of-convolutional-neural-networks/
At first I thought it was some magic, then I found not it is simply add a 1*1 kernel convolutional layers and adjust the output channel arguments. that’s all. if the output channels increase. the feature map is increased. vice versa.
With this skill, they built googleNet.
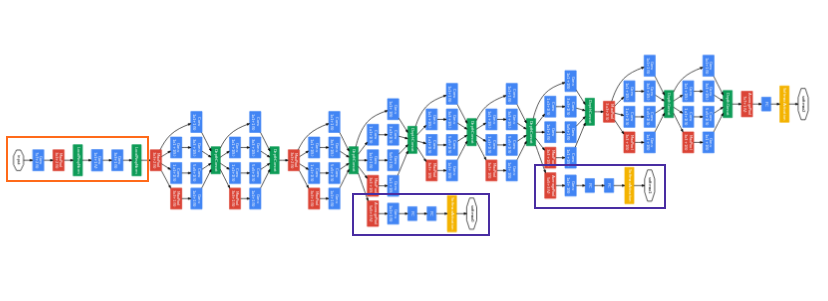 GoogLeNet. The orange box is the stem, which has some preliminary convolutions. The purple boxes are auxiliary classifiers. The wide parts are the inception modules. (Source: Inception v1)
GoogLeNet. The orange box is the stem, which has some preliminary convolutions. The purple boxes are auxiliary classifiers. The wide parts are the inception modules. (Source: Inception v1)
GoogleNet has 9 inception modules stacked linearly. It is 22 layers deep which is very deep. With this depth, it is subject to the vanishing gradient problem.
to prevent it from dying out in the middle. The designer introduced two auxiliary classifier, They essentially appied softmax to the outputs of two of the inception modules.
Inception 2 and further network structure will be talked about later.
https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202