Visual reognition for on device and embedded applications poses mnay challenges:
- model must run quickly with high accuracy
- resource-constrained environment
THis paper describes an efficient network and a set of two hyper-parameters in order to build very samll, low latency models.
previous work:
- Depthwais seperable convolutions
- Flattened networks.
- Factorized networks
- Xception network
- Squeezenet
- different approach: Shrinking
- Another method for training small network:
- distillation: which use a larger network to teach a small network, this is complementary to mobilenet and is covered in section 4.
mobilenet architecture
- distillation: which use a larger network to teach a small network, this is complementary to mobilenet and is covered in section 4.
seperable convolution :https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
why does spatial seperable convolution reduce multiplication?
traditional convolution:
input: $D_F * D_F * M$ output: $D_G * D_G N$ kernel:$D_kD_kMN$ computational cost: $D_KD_KMND_F*D_F$
 </a>
</a>
width multiplier:
$\alpha$ channels: $\alpha M$, $\alpha N$
Resolution multiplier:
MObileNet_v2: inverted Residuals and Linear bottleneck.
inverted residuals:
- original residual blocks: wide-narrow-wide
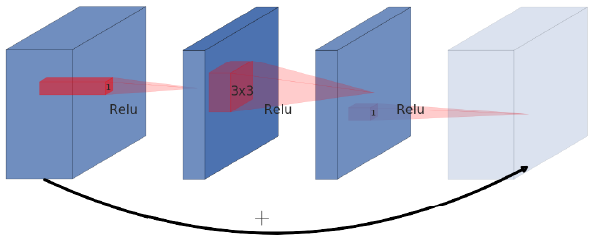
- inverted: narrow - wide- narrow
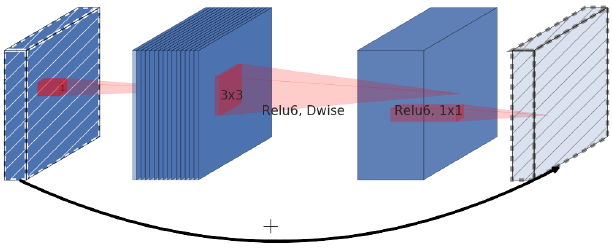
### linear bottleneck
remove the last activation layer before the last convolutional layer.
### relu 6 instead of relu
## MobileNet V3
### Squeeze-and-Excitation networks https://towardsdatascience.com/squeeze-and-excitation-networks-9ef5e71eacd7 ### Platform-Aware NAS for Block-wise Search.
### hard-swish activation layers.